AI Crawl Control now includes new tools to help you prepare your site for the agentic Internet—a web where AI agents are first-class citizens that discover and interact with content differently than human visitors.
Content Format insights
The Metrics tab now includes a Content Format chart showing what content types AI systems request versus what your origin serves. Understanding these patterns helps you optimize content delivery for both human and agent consumption.
Directives tab (formerly Robots.txt)
The Robots.txt tab has been renamed to Directives and now includes a link to check your site’s Agent Readiness score.
Cloudflare’s network now supports redirecting verified AI training crawlers to canonical URLs when they request deprecated or duplicate pages. When enabled via AI Crawl Control > Quick Actions, AI training crawlers that request a page with a canonical tag pointing elsewhere receive a 301 redirect to the canonical version. Humans, search engine crawlers, and AI Search agents continue to see the original page normally.
This feature leverages your existing <link rel="canonical"> tags. No additional configuration required beyond enabling the toggle. Available on Pro, Business, and Enterprise plans at no additional cost.
AI Search now supports hybrid search and relevance boosting, giving you more control over how results are found and ranked.
Hybrid search
Hybrid search combines vector (semantic) search with BM25 keyword search in a single query. Vector search finds chunks with similar meaning, even when the exact words differ. Keyword search matches chunks that contain your query terms exactly. When you enable hybrid search, both run in parallel and the results are fused into a single ranked list.
You can configure the tokenizer (porter for natural language, trigram for code), keyword match mode (and for precision, or for recall), and fusion method (rrf or max) per instance:
Relevance boosting lets you nudge search rankings based on document metadata. For example, you can prioritize recent documents by boosting on timestamp, or surface high-priority content by boosting on a custom metadata field like priority.
Configure up to 3 boost fields per instance or override them per request:
New AI Search instances created after today will work differently. New instances come with built-in storage and a vector index, so you can upload a file, have it indexed immediately, and search it right away.
Additionally new Workers Bindings are now available to use with AI Search. The new namespace binding lets you create and manage instances at runtime, and cross-instance search API lets you query across multiple instances in one call.
Built-in storage and vector index
All new instances now comes with built-in storage which allows you to upload files directly to it using the Items API or the dashboard. No R2 buckets to set up, no external data sources to connect first.
The new ai_search_namespaces binding replaces the previous env.AI.autorag() API provided through the AI binding. It gives your Worker access to all instances within a namespace and lets you create, update, and delete instances at runtime without redeploying.
Within the new AI Search binding, you now have access to a Search and Chat API on the namespace level. Pass an array of instance IDs and get one ranked list of results back.
constresults=awaitenv.AI_SEARCH.search({
messages: [{ role:"user", content:"What is Cloudflare?"}],
Artifacts is now in private beta. Artifacts is Git-compatible storage built for scale: create tens of millions of repos, fork from any remote, and hand off a URL to any Git client. It provides a versioned filesystem for storing and exchanging file trees across Workers, the REST API, and any Git client, running locally or within an agent.
You can read the announcement blog to learn more about what Artifacts does, how it works, and how to create repositories for your agents to use.
Artifacts has three API surfaces:
Workers bindings (for creating and managing repositories)
REST API (for creating and managing repos from any other compute platform)
Git protocol (for interacting with repos)
As an example: you can use the Workers binding to create a repo and read back its remote URL:
We are renaming Browser Rendering to Browser Run. The name Browser Rendering never fully captured what the product does. Browser Run lets you run full browser sessions on Cloudflare’s global network, drive them with code or AI, record and replay sessions, crawl pages for content, debug in real time, and let humans intervene when your agent needs help.
Along with the rename, we have increased limits for Workers Paid plans and redesigned the Browser Run dashboard.
We have 4x-ed concurrency limits for Workers Paid plan users:
Concurrent browsers per account: 30 → 120 per account
New browser instances: 30 per minute → 1 per second
Rate limits across the limits page are now expressed in per-second terms, matching how they are enforced. No action is needed to benefit from the higher limits.
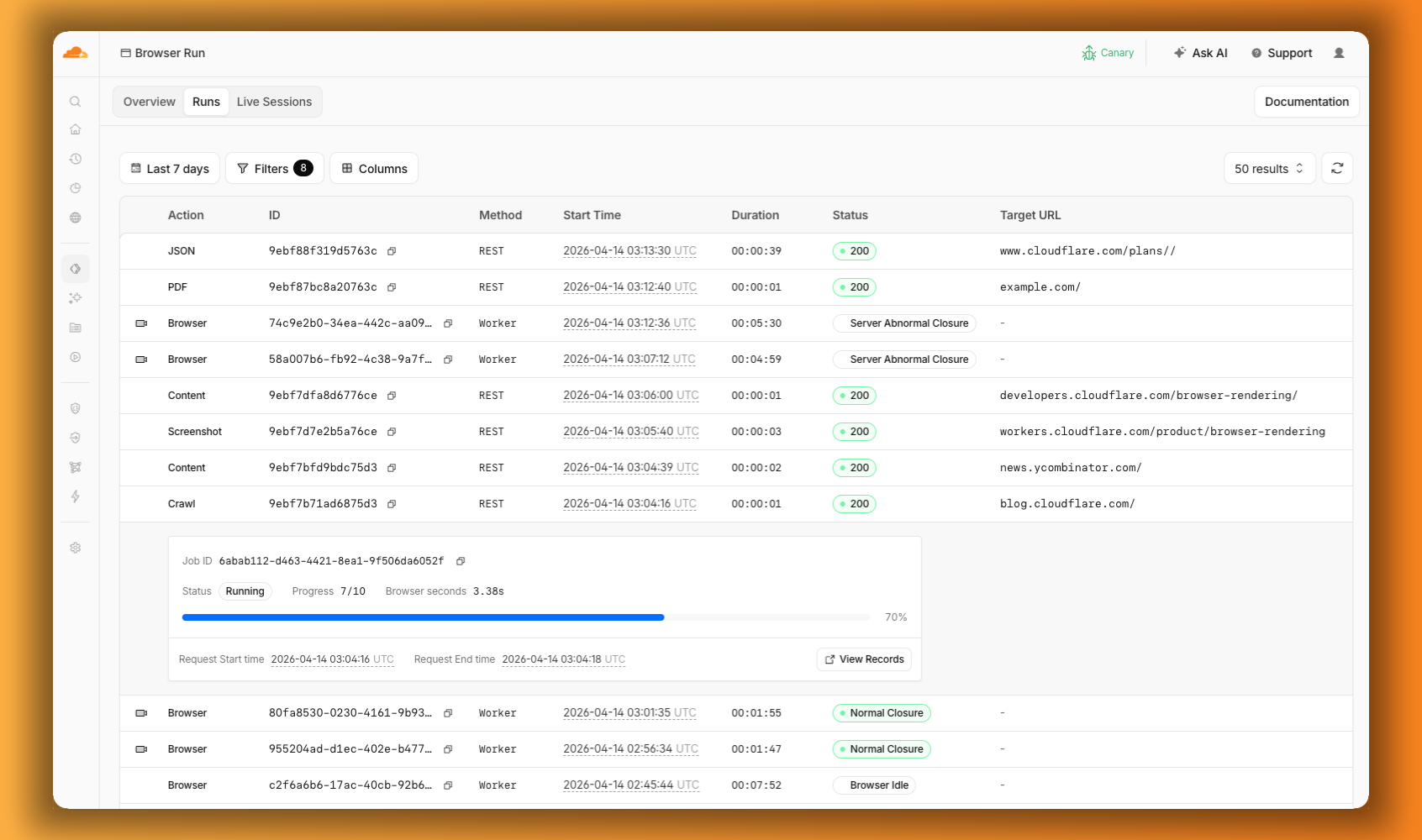
The redesigned dashboard now shows every request in a single Runs tab, not just browser sessions but also quick actions like screenshots, PDFs, markdown, and crawls. Filter by endpoint, view target URLs, status, and duration, and expand any row for more detail.
We are renaming Browser Rendering to Browser Run. The name Browser Rendering never fully captured what the product does. Browser Run lets you run full browser sessions on Cloudflare’s global network, drive them with code or AI, record and replay sessions, crawl pages for content, debug in real time, and let humans intervene when your agent needs help.
Along with the rename, we have increased limits for Workers Paid plans and redesigned the Browser Run dashboard.
We have 4x-ed concurrency limits for Workers Paid plan users:
Concurrent browsers per account: 30 → 120 per account
New browser instances: 30 per minute → 1 per second
Rate limits across the limits page are now expressed in per-second terms, matching how they are enforced. No action is needed to benefit from the higher limits.
The redesigned dashboard now shows every request in a single Runs tab, not just browser sessions but also quick actions like screenshots, PDFs, markdown, and crawls. Filter by endpoint, view target URLs, status, and duration, and expand any row for more detail.
Cloudflare Mesh is now available (blog post). Mesh connects your services and devices with post-quantum encrypted networking, allowing you to route traffic privately between servers, laptops, and phones over TCP, UDP, and ICMP.
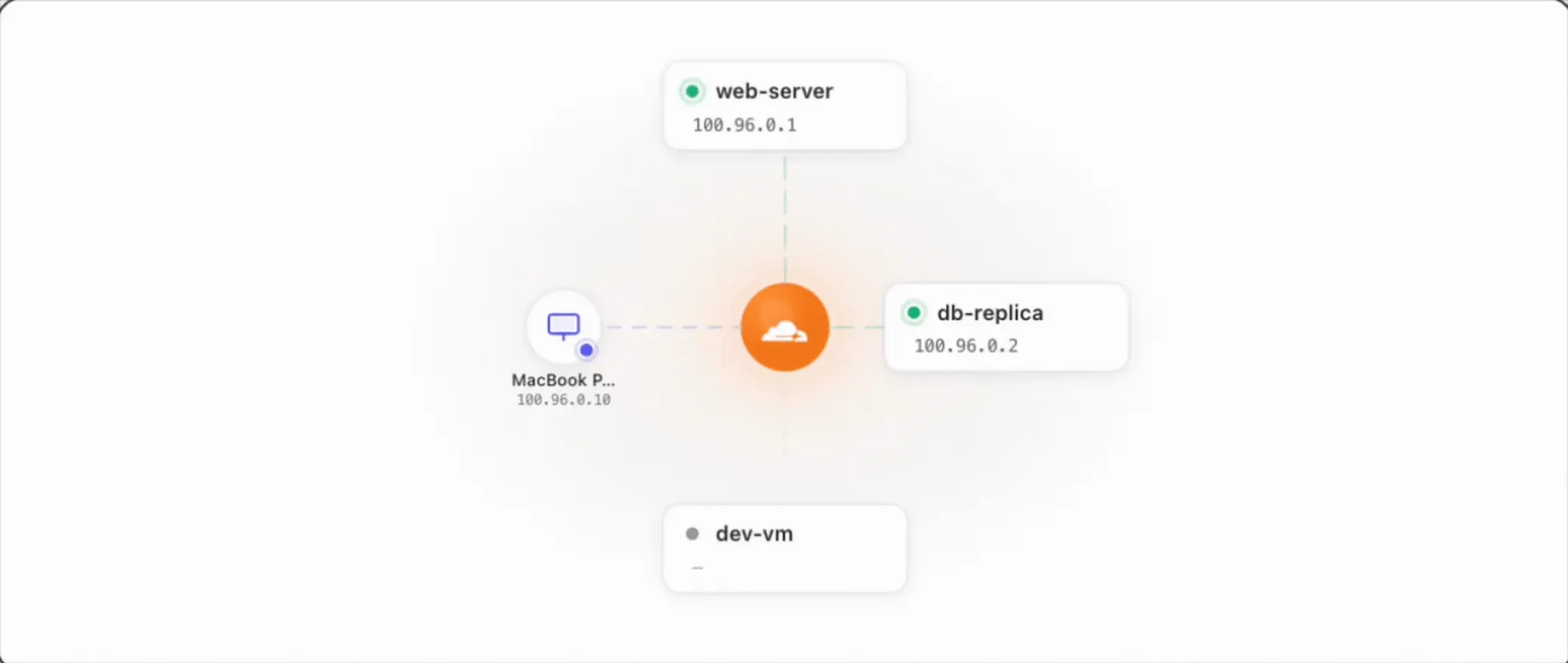
What Cloudflare Mesh does
Assigns a private Mesh IP to every enrolled device and node.
Enables any participant to reach any other participant by IP — including client-to-client, without deploying any infrastructure.
Supports CIDR routes for subnet routing through Mesh nodes.
Supports high availability with active-passive replicas for nodes with routes.
WARP Connector is now Cloudflare Mesh. Existing WARP Connectors are now called mesh nodes. All existing deployments continue to work — no migration required.
Peer-to-peer connectivity is now called Mesh connectivity and is part of the Cloudflare Mesh documentation.
Mesh node limit increased from 10 to 50 per account.
New dashboard experience at Networking > Mesh with an interactive network map, node management, route configuration, diagnostics, and a setup wizard.